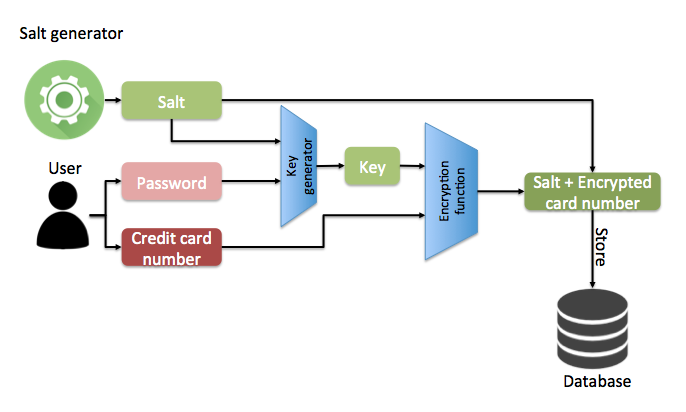
At the end of post "2015, the year in a Breach" (bit.ly/1RqqvG6) we mentioned that the next wave of cyber attacks will not steal information, but alter it. This, was a remark based on a statement made by America’s intelligence chiefs (http://bit.ly/1VS8Pb8).
At the end of post "2015, the year in a Breach" (bit.ly/1RqqvG6) we mentioned that the next wave of cyber attacks will not steal information, but alter it. This, was a remark based on a statement made by America’s intelligence chiefs (http://bit.ly/1VS8Pb8).
We think that this is actually going to happen because on one side there is a profit to be made (don’t rob an ATM, just alter the bank account balance) and, on the other, attackers may be motivated by political or military reasons.
Information may be altered when at rest or when in transit. This means that an attacker can either alter information when it is sitting on your DB or when you are transmitting information from one point to another.
When at rest, it is possible to detect unauthorized data modifications by introducing an hashing “safeguard”. Each time an operation produces any type of changes to the data, a new hash should be calculated and saved. Then, each time an read is required, it is possible to detect changes by hashing the information and comparing to the saved one.
Although this may seem feasible, it is not! At the rate that data grows and although hashing functions are very fast, it would not be practical to compute a hash of the data each time an alteration is made because hashing functions still need to go through every byte of information to produce the hash (just try to hash 100mb and 10gb of info and compare the time it takes).
So how exactly can we detect data changes? The answer to that is both simple and complex at the same time. Assuming that there are replication policies in place, it’s simple because you just have to evolve your fault model and change your replication from passive to active and complex because you have to evolve your fault model and change your replication form passive to active!
To understand what follows, keep in mind the following definitions:
- Fault: occurs when the system stops working properly (commonly know as crash);
- State: represents the status of the system and is the result of all the operations performed on the system;
- Write: any operation that changes the state of the system;
- Read: returns information according to the current state of the system
To sustain faults, systems can be designed to offer high availability (HA). The HA is built on replication where, if there is at least one replica functioning, the system will continue to operate. To ensure HA, system are designed to sustain at most f simultaneous faults. This means that to actually resist f faults, there needs to be at least f+1 replicas in total. So even if f simultaneous faults occur, the system will still function. There are to basic replication models, passive and active.
Most of the current systems rely on passive data replication. In this model there’s an active and a passive replica. The active replica is responsible for backing up writes (operations that change data on the system) asynchronously to the passive replica on a regular basis. When the active replica fails, the passive replica takes over becoming the active.
The asynchronous replication model has two great problems:
- If data gets changed on the active replica, it will not be detected and, will eventually get copied to the passive replica;
- When the active replica fails, the data that was not copied to the passive replica will be lost.
In this model, it is possible to force the active replica to write all changes to the passive replica either before or immediately after writing to itself. Doing this will induce extra time on each write since, the active replica needs to contact the passive in a synchronous way before giving the write as completed to the client.

Passive replication (f=1) - synchronous writes
If we consider that each write takes X time and that the time that a message takes to be propagated on the network is Y, we can compare both synchronous and asynchronous writes for the passive model in terms of time from a client’s perspective:
- Asynchronous = X+Y+Y = X+2Y
- Synchronous = Asynchronous + X+Y+Y = X+2Y + X+2Y = 2(X+2Y) = 2Asynchronous
So in practice, the client needs to wait twice as long for the synchronous write (assuming fair network hops to keep it simple). Even worst, switching from asynchronous to synchronous writes will only guarantee that data will not be lost in case of failure, it will not detect data changes!
In active replication, writes are performed on each replica at the “same time”. When the client sends a message, it sends it to all replicas and waits for the first write to complete. The client just has to wait for the first write to complete since we assume that the system is working properly if there is at least one replica working (remember f+1 replicas with at least one working properly).
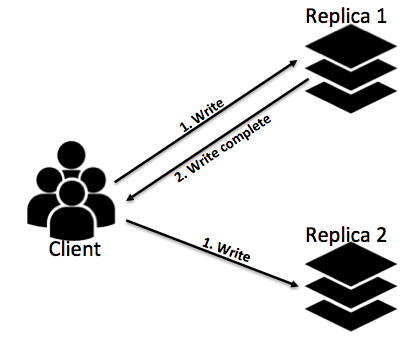
Active replication (f=1)
By direct comparison with the passive replication model, if we consider the same network propagation time Y and the same write time X we see that each write takes the same amount of time of the asynchronous write, X+2Y. We can also see that it gets the same property of the synchronous write that, even if one replica goes down, the system will not lose data. Another common trade with the passive replication model is that we still aren’t detecting data changes. There is also a new problem with this model, the concurrent writes.
Concurrent writes can occur when there are multiple clients sending write operations to the replicas but, these operations arrive at different replicas in different orders (for example due to different network distances). To assure that all replicas execute the writes in the same order, a special intra-replica protocol is required to order the writes.
I will not describe the intra-replica protocol on these posts. If you have a concurrent write problem, I suggest that you either contact me, or the company for which I work.
In this post we explained the key differences between active and passive replication models. On the next one, we will evolve the fault model to detect unauthorized data changes.